NLP_ThumbnailAnnotator
M.Sc. Project in Language Technology at Uni Hamburg from Florian Schneider
Project maintained by uhh-lt Hosted on GitHub Pages — Theme by mattgraham
Developer Guide
This guide will show you the basic architecture and most important components of the REST API to extend or build on it.
- Software Architecure of the API
- Core Module
- Domain Package
- CaptionTokenExtractor Package
CaptionTokenExtractor- Custom
Annotators - Custom
Annotations
- ThumbnailCrawler Package
ThumbnailCrawler
- DB Module
- Redis Configuration
- Subpackages
- API Module
- Components
- Core Module
- REST API Documentation
Software Architecure of the API
The software is written in Java 8 using several Java Frameworks such as UIMA wrapped by DKPro Core, DKPro WSD and Spring-Boot and is structured as a multi-module Maven project. The parent module pom.xml holds the basic configuration, properties, plugins & dependencies which are required in all of the three modules and is located in the thumbnailAnnotator.parent directory. This directory, which is the is the root directory for the whole project, holds the three main modules and should be imported as a Maven project from the IDE of your choice. A diagram of how the modules interact is shown below.
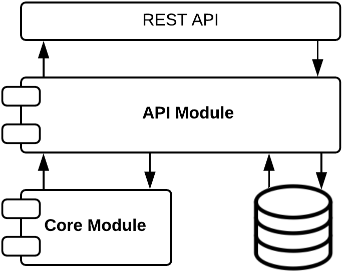
Core Module
This module holds the business logic as well as the domain model. The module is further devided into multiple packages:
Domain Package
This package holds the domain model. All of the POJO classes in this package inherit from the DomainObject class, to indicate that they are part of the domain model. The main components of the domain model are the CaptionToken, the Thumbnail, the ExtractorResult and the CrawlerResult.
-
A
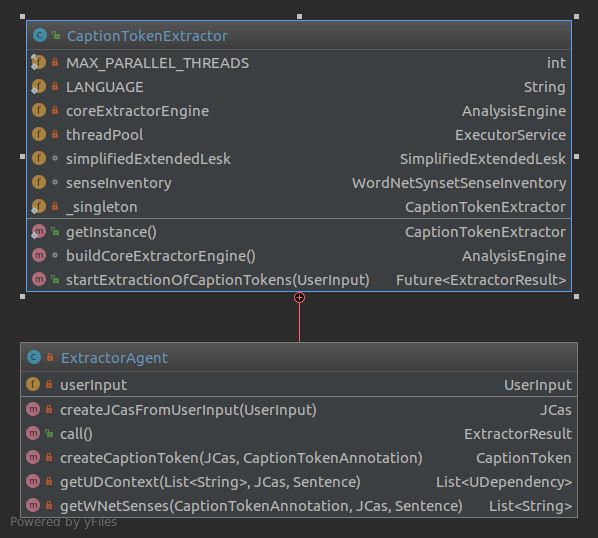
CaptionTokendescribes the constituents of an input text, for whichThumbnails are searched / crawled. Those constituents are Nouns with or without modifiers/adjectives (e.g. ‘bird’ or ‘distant hight mountains’) and Named Entities such as Persons, Organizations and Locations (e.g. ‘Siddartha’, ‘New York’ or ‘Microsoft’). A UML diagram of aCaptionTokencan be seen below. The members of theCaptionTokenget described by their names.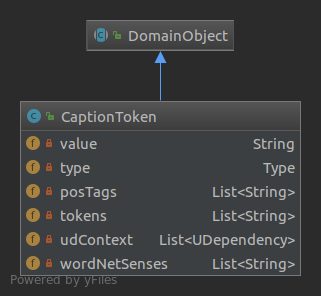
-
A
Thumbnailrepresents a visual description of aCaptionTokenin form of a URL, that’s pointing to the image, as well as a a priority that indicates how good theThumbnaildescribes theCaptionToken. The priority of aThumbnailis initialized with ‘1’ and can be incremented or decremented by Users through the API later on.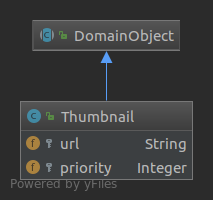
-
A
ExtractorResultis the result of theCaptionTokenExtractorand bundles allCaptionTokens that were extracted from aUserInput. More details are described in the section of theCaptionTokenExtractor. -
A
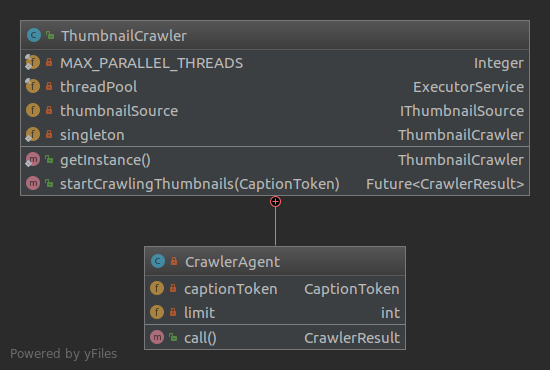
CrawlerResultis the result of theThumbnailCrawlerwhich holds aCaptionTokenand a list ofThumbnails that were crawled for this particularCaptionToken. More details are described in the section of theThumbnailCrawler.
CaptionTokenExtractor Package
CaptionTokenExtractor
This package contains the CaptionTokenExtractor - the main component to extract CaptionTokens from a UserInput. It is designed as a Singleton class and it’s core functionallity is implemented using the UIMA Framework wrapped by the DKPro Core Framework and DKPro WSD. The CaptionTokenExtractor contains a managed ExecutorService since the extraction happens in parallel. For each UserInput an ExtractorAgent gets instantiated, which extracts the CaptionTokens.
To extract CaptionTokens, an aggregated AnalysisEngine is used to create CaptionTokenAnnotations, which are then transformed to CaptionTokens. This aggregated AnalysisEngine consits of the following Annotators, where the Annotators 6. - 9. are a custom Annotators and get’s created by the CaptionTokenExtractor.
OpenNlpSegmenterClearNlpPosTaggerClearNlpLemmatizerMaltParserOpenNlpNamedEntityRecognizerwith variants- location
- person
- organization
PosExclusionFlagTokenAnnotatorNamedEntityCaptionTokenAnnotatorPosViewCreatorNounCaptionTokenAnnotator
Custom Annotators
The following custom Annotators can be found in the nlp.floschne.thumbnailAnnotator.core.captionTokenExtractor.annotator package.
PosExclusionFlagTokenAnnotatorAnnotatorto create thePosExclusionFlagTokens for everyPOS-Tag from theSegmenterand initialized as not used.
NamedEntityCaptionTokenAnnotatorAnnotatorto createCaptionTokens that hold Named Entities. It sets the exclusion flags of thePosExclusionFlagTokens, which are covered by the createdCaptionTokens, to true so that they’re excluded later on, when creating theCaptionTokens that hold Nouns.
PosViewCreatorAnnotatorthat doesn’t createAnnotationsbut aJCasView that holds thePOS-Tag values of theTokens. E.g. only ‘JJ PUNCT JJ NNS’ for ‘blue, pale birds’.
NounCaptionTokenAnnotatorAnnotatorto createCaptionTokens that hold Nouns.
Custom Annotations
This Annotations are described by XML files located at src/main/resources/desc.type and are generated by the JCasGen Maven Plugin during the generation phase of Maven.
PosExclusionFlagToken- This is the same as a
POSfrom a POS-Tagger but has a flag wether or not it should be excluded of not in order to create aCaptionTokenAnnotation.
- This is the same as a
ViewMappingToken- A
Annotationthat holds the start and end position in anotherJCasView to map between the two Views. E.g. ATokenwith surface ‘bird’ in default View has start and end [4, 7]. In another View that holds onlyPOS-Tag (‘NN’) it has start and end [2, 4]. TheViewMappingTokencontains both start and end positions from the two Views.
- A
CaptionTokenAnnotation- This
Annotationrepresents aCaptionTokenat UIMA level. It holds all the information to create aCaptionTokenat domain model level.
- This
ThumbnailCrawler Package
ThumbnailCrawler
This package contains the ThumbnailCrawler - a Singleton class to search the Thumbnails for a given CaptionToken. This is done pretty straightforward by quering a IThumbnailsource with a CaptionToken. In the current version there is one implementation of the interface - the ShutterstockSource - but additional implementations could be used very easy.
In order to receive a specified number of URLs to the images, the value of the CaptionToken is used as query parameter to make a HTTP GET request to the Shutterstock REST API. If the number of returned results is less than the specified, only the head/last Token of the CaptionToken is used since it holds the most general description. Then, for each of those URLs a Thumbnail get’s instantiated and it’s priority is initialized with ‘1’.
The ThumbnailCrawler contains a managed ExecutorService since getting Thumbnails is done in parallel. For each CaptionToken a CrawlerAgent gets instantiated which performs the crawling for that CaptionToken.
DB Module
As the name suggests, in this module the database layer is located. The database used, is the famous NoSQL, in-memory database called Redis. The module uses the simple Key-Value-Store to store the Entitys by an Id of type String. To make things easy and accessible in the API module the Module heavily depends on the Spring-Boot Framework, specially the Spring-Boot-Data-Redis Component. This package has high code coverage since it’s curcible for the overall functionallity of the API.
Redis Configuration
The connection to Redis is configured in the RedisConfig. There are two Spring profiles, that specify the connection to the database when running the API locally or inside docker-compose.
Subpackages
The module has four subpackages:
- entity
- This subpackage contains the
EntitiyPOJOsThumbnailEntity,CaptionTokenEntitiyandCrawlerResultEntitywhich are the Entity/DTO representations of the respectiveDomainObjects from the domain model in the Core Module. Those POJOs are persisted in a Redis Key-Value-Store.
- This subpackage contains the
- mapper
- This subpackage contains the
IMapperextensions to map between theEntitiyandDomainObjectPOJOs. The implementations of the interfaces in this package get generated during the build phase of Maven by the MapStruct Code Generator.
- This subpackage contains the
- repository
- This subpackage contains the
CURDRepositoryinterfaces used to store and receive the respectiveEntitiesfrom theentitiypackage. - service
- This subpackage holds the
DBService, which is a@Serviceclass that wraps, extends and eases access to the repositories. This is mostly used in the API Module. Since the
- This subpackage holds the
API Module
This module is responsible to expose the REST API Resources in order to interact with the Thumbnail Annotator. It connects the domain model functionallity of the Core Module with the DB Module. Since this package should hold as less logic as possible there are only three classes. The module also heavily depends on the Spring-Boot Framework, specially the Spring-Boot-Starter-Web Component.
Components
Application- This is the class that holds the main-function of the project and therefore is the main entry point. Since it’s a
SpringBootApplicationit loads theAPIControllerclass in the Context and exposed the resources with an internal TomCat-Server.
- This is the class that holds the main-function of the project and therefore is the main entry point. Since it’s a
APIController- This is the main component of the API and specifies and exposes the API Resources. Since the code is very well documented, please have a look at it to get more details.
SwaggerConfig-This class configures the Swagger-UI
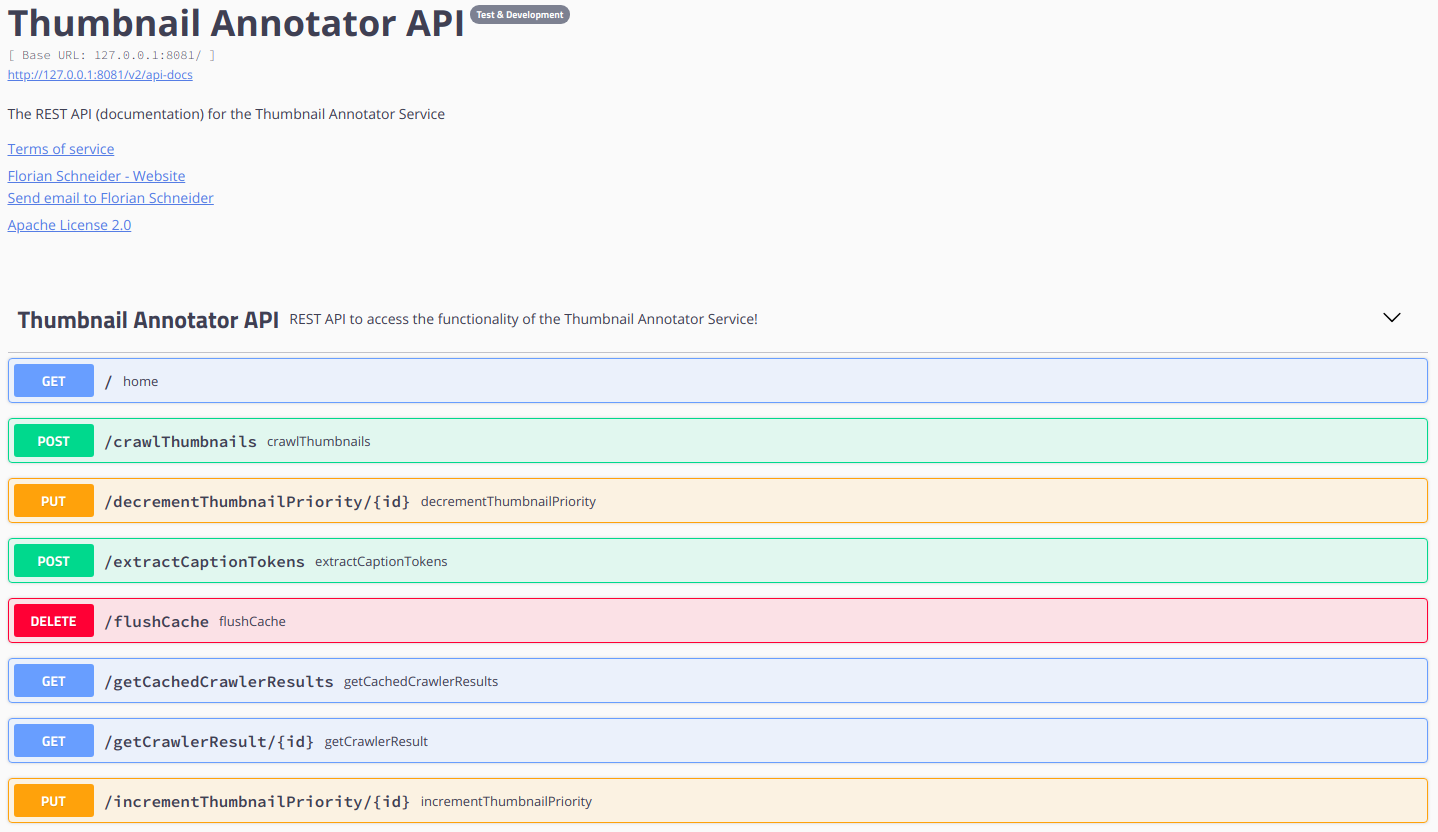
REST API Documentation
The RESTful API is documented by a Swagger-UI implemented with Springfox which can be found when opening localhost:8081 in a browser (assuming the API is running!). A screen shot of the header as well as the methods part of the Swagger-UI can be seen below.