SenseGram
This repository contains implementation of a method that takes as an input a word embeddings, such as word2vec and splits different senses of the input words. For instance, the vector for the word "table" will be split into "table (data)" and "table (furniture)" as shown below.
Our approach performs word sense induction and disambiguation based on sense embeddings. Sense inventory is induced from exhisting word embeddings via clustering of ego-networks of related words, such as one shown on the image below.
Detailed description of the method is available in the original paper:
If you use the method please cite the following paper:
@InProceedings{pelevina-EtAl:2016:RepL4NLP,
author = {Pelevina, Maria and Arefiev, Nikolay and Biemann, Chris and Panchenko, Alexander},
title = {Making Sense of Word Embeddings},
booktitle = {Proceedings of the 1st Workshop on Representation Learning for NLP},
month = {August},
year = {2016},
address = {Berlin, Germany},
publisher = {Association for Computational Linguistics},
pages = {174--183},
url = {http://anthology.aclweb.org/W16-1620}
}
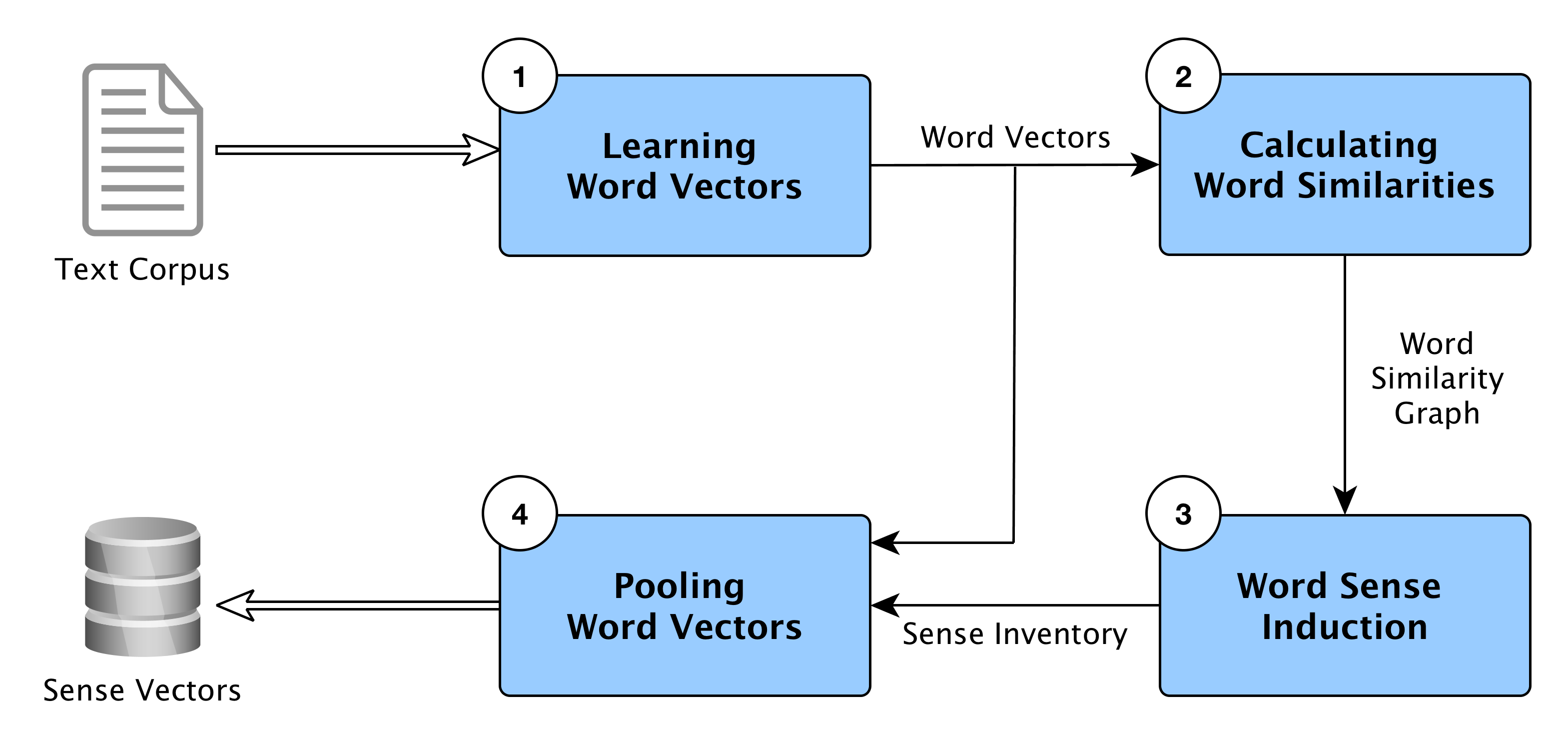
Learning of word sense embeddings
The picture below shows the overall architecture of word sense embedding learning from word senses.
Word sense induction
Word senses are obtained by clustering of related words. This is an example of the word ego-network clustering. We use the Chinese Whispers algorithm.

Word sense disambiguation
Once sense vectors are obtained, these can be used for disambiguation of words in context based on cosine similarity between context words and word prototypes.

Contact
If you have any question, please use the email indicated in the original paper or simply create a Github issue.